
The challenges of applying Artificial Intelligence
Artificial Intelligence’s (AI) unstoppable advance is creating a growing gap between companies that have already adopted it and those that are starting to use it. Also, the firms that started with a proof of concept that has not achieved the expected great, immediate result, may experience a small frustration and opt for a “wait-and-see” strategy.
Professor’s Erik Brynjolfsson (Stanford) J-curve concept perfectly defines this initial phase:
“These investments and changes often take several years, and during this period, they don’t yield tangible results. During this phase, the companies are creating “intangible assets”. For example, they might be training and reskilling their workforce to employ these new technologies. They might be redesigning their factories or instrumenting them with new sensor technologies to take advantage of Machine Learning (ML) models. They might need to revamp their data infrastructure and create data lakes on which they can train and run ML models. These efforts might cost millions of dollars (or billions in the case of large corporations) and make no change in the company’s output in the short term.”
All this makes bigger the gap between those who are convinced and those who prefer to wait. According to a recent research from the McKinsey Global Institute, there is a real and growing gap between the leaders and the laggards in the application of AI, both between the sectors where it is applied and within them.
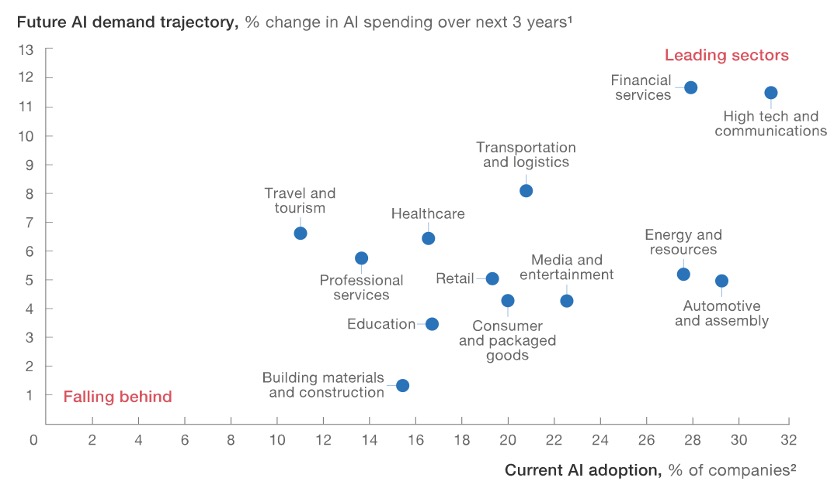
Among the most common challenges faced by companies starting AI projects are the lack of data or the lack of specialized personnel. In some cases, companies face both, which requires large initial investments.

Most of the current AI models are trained through "supervised learning". This means that humans must label and categorize data, which can be a considerable task. Unsupervised approaches reduce the need for large labeled data sets; however, they can’t be applied in many use cases. The use of supervised or unsupervised models is inherently linked to the use case (visit Machine learning, explained for more information).
Furthermore, the most advanced Machine Learning techniques, such as Deep Learning, require data sets for training that are not only labeled, but also large and complete enough. Massive data sets can be difficult to obtain or create. Both the massive collection of data and their preparation and labeling can represent a significant investment.
We must not forget the challenge of talent. In this case, we can make up for short-term lacks through outsourcing. But outsourcing the whole AI can be a huge mistake.
Business leaders hoping to bridge the aforementioned gap must be well-informed before approaching AI. That is, they must be able to understand for themselves the points where AI can bring revenue growth or capture efficiencies. They must also know how to distinguish where AI does not provide any value.
Furthermore, we have already discussed that they (and not technical profiles) are responsible for understanding and solving the “last mile” challenge of incorporating AI into products and processes.
Son retos que señalan un roadmap de varios años para las empresas. Ese camino difícilmente nos lo podremos ahorrar. Pero sí que podemos empezar a utilizar y experimentar rápidamente con herramientas de aprendizaje automático, conjuntos de datos y modelos entrenados para aplicaciones estándar, los cuales están ampliamente disponibles.
These challenges set a roadmap of several years for companies, with processes that we can hardly avoid. But what we can do is quickly start using and experimenting with Machine Learning tools, data sets, and trained models for standard applications, which are widely available.
This is “ready to use” AI or off-the-shelf AI, which includes, for example, the detection and creation of natural language and artificial vision models. Sometimes, they come in open source and, in other cases, through application programming interfaces (APIs) created by pioneering companies like OpenAI or large public cloud providers like AWS, Microsoft or Google.
The image below shows the main use cases offered by AWS off-the-shelf AI technology.

There are companies that are already implementing off-the-shelf AI solutions, either using natural language models, such as PauBot, the student service chatbot that we developed for the Generalitat de Catalunya; or artificial vision solutions, such as the identity validation system for online assessments that we created for a prestigious online university, which helped reduce fraud in exams taken remotely.
In practice, we must be able to combine both approaches and have the necessary skills to design the ideal solution in each case. For standardized use cases, we have off-the-shelf AI models that can be implemented with cloud architecture and data architecture capabilities, working together with domain experts.
For non-standardized cases, we must also have data science capabilities that accompany us in the decision-making and creation of the AI model.

The potential of AI is immense and the technologies that should make it a reality are still in development.
If you feel that it is the moment to think about long-term business survival and take a stance on the new era of data-driven companies, contact us and we will help you. Without forgetting the challenges of the most customized and ambitious AI application with data science, we can rely on off-the-shelf AI to solve different use cases in a really fast and effective way.
And, if you want to know more about IA, remember that we have explained the data challenge for Artificial Intelligence, listed the 4 types of data to apply AI and addressed the importance of the 3 knowledge roles of AI team members.








