
The data challenge for Artificial Intelligence
Data are fundamental to Artificial Intelligence (AI) and, luckily, they are ubiquitous. The issue is how we manage them. Let's think about our own organization: Can we handle them? Are they accessible? Are they unified or, on the contrary, accumulated in multiple silos and different formats within the organization?
This is where the data platform and data architecture come into play.
The data platform is the machine that accesses, moves, analyzes, correlates and validates data for end users.
A very common situation in companies is the implementation of point solutions used to provide data services in different departments. Many times, these are product-type solutions, which limit the ability to scale and do not offer a holistic view of the company. Instead, a true data platform (or big data platform) integrates the capabilities of those solutions and brings all data together centrally, in one only place where they can be protected, shared, and used most effectively.
The data architecture is the plan for ingesting, storing, and delivering data. It is essentially a framework for an organization's data environment.
A correct data architecture continues to be a real challenge for companies. And with the growing volume of data and technologies like 5G and the Internet of Things (IoT), having strong architectural principles is becoming more and more important.
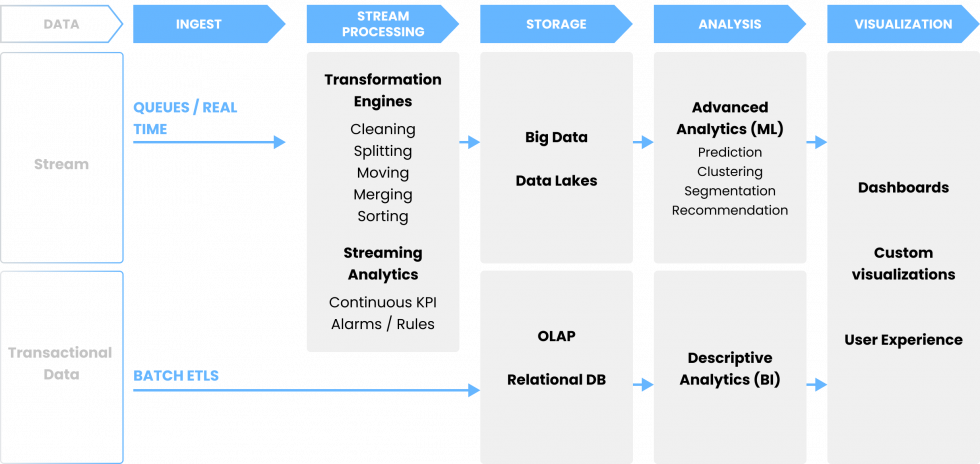
Real-time streaming features, such as a subscription mechanism like the one of Sentilo in the Barcelona City Council, allow to subscribe to "topics”, so they can get a constant source of the transactions needed.
A shared datalake typically serves as the "brain" for such services. Furthermore, there is a trend to recover a sense of business or domain that goes through moving from a central datalake, to “domain-based” designs that can be customized by “data owners” or “product owners”.
With this so-called “data mesh” approach, while data sets may still reside on the same physical platform, “product owners” in each business domain (marketing, HR, etc.) are tasked with organizing their data sets in an easily consumable format.
Finally, it is worth highlighting the cloud as the most disruptive booster of a radically new data architecture approach, as it offers companies not only a way to scale quickly, but also a series of additional services of great value that we will see later. Public clouds serverless data platforms enable organizations to build and operate self-managing data-centric applications with infinite scale, in addition to the horizontal scaling and implementation facilities offered by containerized data solutions.
If you want to move forward, we suggest you to read "4 types of data to apply Artificial Intelligence"… and, if you need help in adopting AI and Machine Learning, contact us!








